机器学习算法类型
我们先来简单了解一下机器学习算法的四种类型:有监督学习、无监督学习、半监督学习、增强学习,也叫强化学习。这四种类型构成了机器学习领域的基本框架,每种算法都适用于不同的问题场景和数据特征。
有监督学习和无监督学习
常见的机器学习算法可以被分为有监督学习和无监督学习两类。下图画出了一个简单的例子。
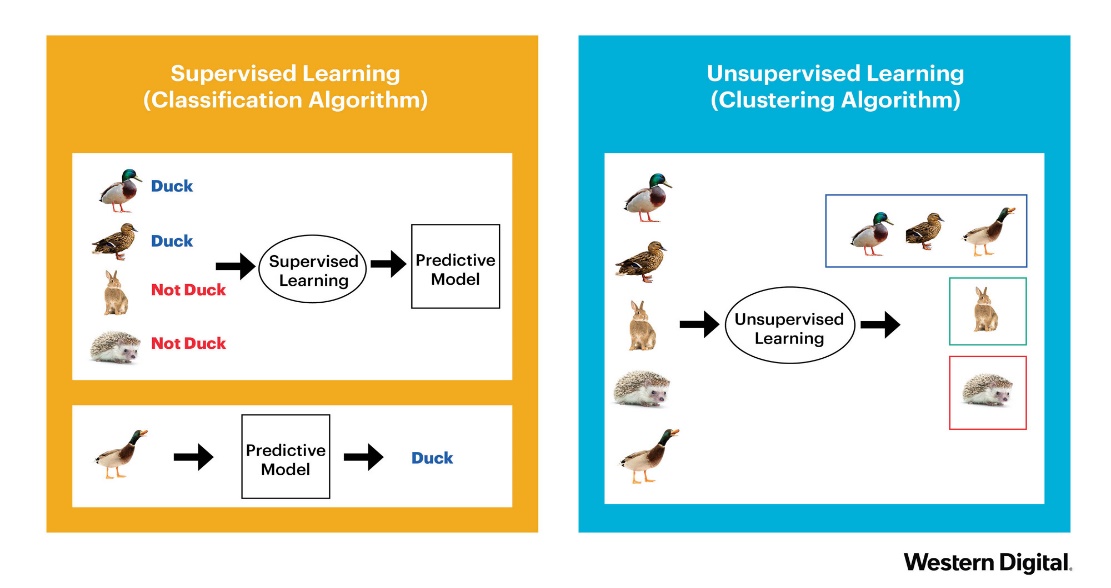
如上图的左小图所示,有监督学习的特点是数据有明确的标签,算法通过这些标签学习正确的模式。例如,我们在教孩子认识动物的图片时,会告诉他们正确答案(上面两个动物是鸭子,下面两个动物不是鸭子),并指出错误,帮助他们改进。类似地,在图片分类任务中,我们会为每张图片打上标签,比如“猫”或“狗”,然后用这些标注好的数据来训练机器学习模型,最终让模型学会准确地分辨图片的类别。
无监督学习则没有正确答案或明确的标签。它更多依赖于数据本身的特性进行分类或聚类。如上图的右小图所示,我们并不告诉孩子正确答案(上面两个动物是鸭子,下面两个动物不是鸭子,最后一个又是鸭子,而是让孩子自己看这 5 个动物,把相似的动物分成一组。类似的,在机器学习的聚类任务中,我们也给算法一组未标注的图片,它会自动将相似的图片分成不同的组。我们并不需要告诉算法哪张图片是“猫”还是“狗”,它只需根据图片的特征自行划分。这种方法非常适合处理没有标签的数据。
总结来说,有监督学习是通过明确指导来学习,而无监督学习则更像是“自学”,依赖于数据间的内在联系。
有监督学习的步骤
在有监督学习中,整个过程可以分为三个主要步骤:打标、训练和测试。
第一步是打标。我们首先收集数据集,然后为这些数据打上正确的标签,这个过程在机器学习领域被称为“打标”。比如,在图片分类任务中,如果我们用到的是监控视频数据,就需要为每一帧画面标注出具体内容:这是“猫”,那是“狗”;或者如果我们在监测接触网异常情况时,就要指出某个具体位置出现了问题。
打标是不可避免的一步,因为有监督学习算法需要依赖这些准确的标签来学习数据中的规律。然而,打标工作需要投入大量的时间、人力和资金成本。比如,一个人一天的工作可能只能完成有限数量的标注任务。因此,数据量的规模和标注的质量对于训练效果至关重要。
打标阶段是有监督学习的基础,之后的训练和测试都依赖于高质量的标注数据。
在完成数据打标后,我们需要将数据集分成三部分:训练集、验证集和测试集,分别用于不同的目的:
- 训练集:用于训练模型,让模型从数据中学习模式和规律。
- 验证集:用于选择模型的参数,例如调整超参数,以提高模型的性能。
- 测试集:用于最终评估模型的准确性,验证模型在未见数据上的表现。
有了数据集后,我们训练模型,这个过程分为三个关键环节:
- 训练:在这一阶段,模型通过训练集学习数据中的模式。算法会反复调整内部参数,以尽可能降低预测错误率。
- 验证:训练完成后,使用验证集来评估模型的表现。验证集可以帮助我们选择模型的最佳参数,例如学习率、正则化强度等,从而避免模型过拟合或欠拟合。
- 测试:在最终阶段,用测试集对模型进行评估,以了解模型的真实性能。测试集的数据完全独立于训练和验证集,能够有效检验模型的泛化能力。
通过这三个环节,模型从数据中逐步学习并优化,最终成为一个能够准确预测新数据的工具。
无监督学习:从无标签数据中寻找规律
与有监督学习不同,无监督学习的数据是没有标签的。它的目标是通过分析数据本身的特性,自动挖掘出隐藏的规律或模式。无监督学习的灵活性使它在处理海量未标注数据时具有强大的优势,尤其适用于探索数据规律和发现潜在结构。以下是几种常见的无监督学习方法。
聚类
聚类将数据划分为若干组,使得同组数据相似度较高,而不同组之间相似度较低。例如,将客户分为不同的消费群体,以便制定差异化的营销策略。
K-means 是一种经典的聚类算法,它能够自动将数据分为 \(K\) 个簇。这里的 \(K\) 是我们事先指定的参数。比如我们先要把数据分成三个簇,我们就指定 K = 3。然后机器就会不断尝试,把数据分为三簇。由于算法具有一定的随机性,每次运行可能会得到略有差异的结果,这是正常的。下图画出了我们对大量数据继续 K-means 的结果。
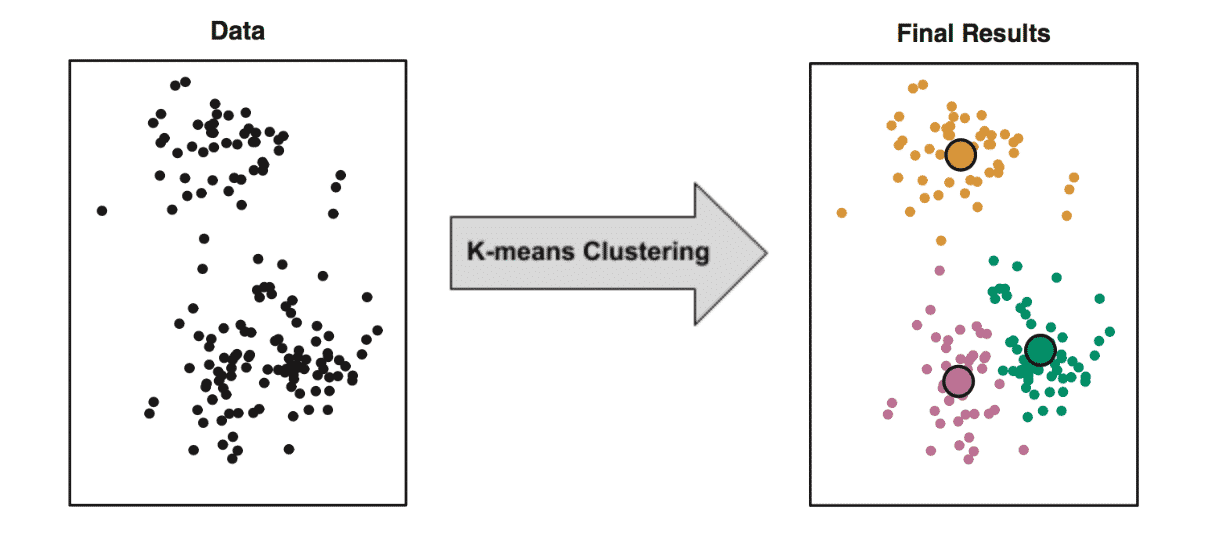
如上图所示,我们指定 K = 3 后,机器学习算法就会不断尝试,最后把数据分为三簇。
在完成聚类后,我们可以观察每个簇的数据特征,从中提取出具有实际意义的信息。例如,一个簇里可能都是小狗,另一个簇里可能都是大狗。
聚类的优势在于它不需要对数据进行标注。比如,我们不需要标注这些图片是小狗还是大狗。因此,我们可以利用它对数据进行初步的分类和观察。这尤其适用于大量复杂数据的探索性分析,快速发现数据中的潜在结构和规律。
异常检测:发现数据中的离群点
异常检测识别数据中不符合常规模式的部分,也就是“异常点”。这一技术在金融欺诈检测、设备故障诊断等领域有广泛应用。通过无监督学习,我们可以进行异常检测,即从数据中发现那些显著偏离常规模式的“离群点”。
离群点检测是异常检测中最简单的一种算法。设想我们有大量数据,每个数据点都可以表示为一个向量。在分析这些向量时,如果某些点的位置显著偏离其他数据点,这些点就会被识别为异常点。下图画出了一组数据的二维向量的示意图。
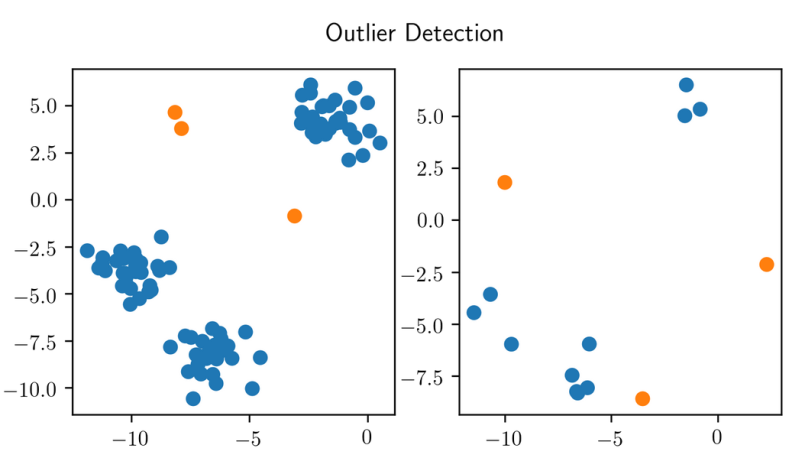
如上图所示,其中的黄色的点显著偏离其它数据点,因为我们就将它们识别为可能的异常点。
异常检测在许多领域都有重要应用:
- 在视频监控中,异常检测可以帮助我们识别异常行为或事件。
- 在医学领域,它被用来检测如脑部扫描中的异常区域,为疾病诊断提供支持。
- 在系统运维中,异常检测可以快速定位设备或系统的异常,为及时修复和优化提供依据。
这种方法能够高效处理海量数据,帮助我们在复杂的环境中快速发现问题,提升工作效率和决策能力。
自编码:压缩与提取数据的关键信息
自编码(Autoencoder)通过神经网络对数据进行压缩和还原,提取出数据的核心特征。它可以用于降维、去噪或生成数据等任务。下图画出了它的工作原理。
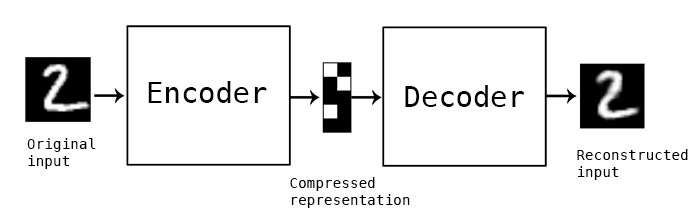
如上图所示,自编码的过程包括两个主要阶段:
- 编码(Encoding):将原始数据进行压缩,提取出其核心特征,形成数据的“压缩表征”(也称为 Code)。
- 解码(Decoding):通过压缩表征还原出原始数据,尽量保持还原后的数据与原数据接近。
这种压缩和恢复的过程让自编码器能够专注于数据中最重要的部分,而忽略噪声或不重要的信息。
通常,自编码器使用深度神经网络作为编码器和解码器的基础。例如,一个自编码器的编码器部分可能由几层神经元构成,用来将高维数据映射到低维空间;而解码器则通过对低维表示的反向操作重建数据。
自编码器被广泛应用于数据降维、图像去噪、特征提取等领域,是深度学习中一种强大的无监督学习工具。
主成分分析(PCA)
主成分分析(Principal Component Analysis, PCA) 是一种用于高维数据的降维方法。它通过正交分解去除数据维度之间的相关性,能够在保持数据主要信息的同时,减少数据的维度,方便进一步处理和可视化。
下图画出了 PCA 的效果。其中,左小图是原始数据,它是 3 维的。经过 PCA 后,它被转换为了如右小图所示的 2 维数据。
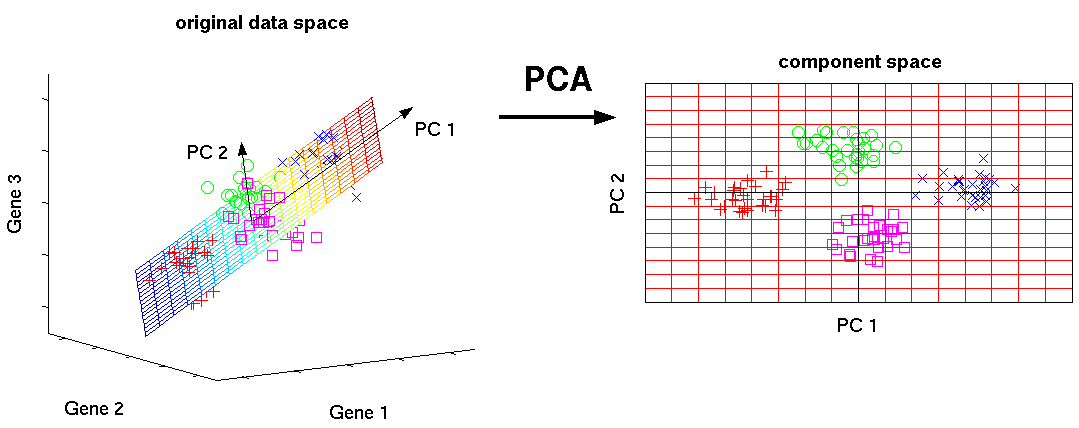
如上图所示,左小图的原始数据虽然是 3 维的,但这些数据点基本上都在一个平面上,这就意味着它的 3 维数据之间存在很强的相关性,更具体一点说,就是其中一维可以由另外的两维通过一个线性公式算出来。因此,PCA 就能感知这种维数之间的相关性,把这些相关性消除,最后把数据变为 2 维的。
那么,我们为什么要用 PCA 消除数据维度之间的相关性呢?这样做的好处有以下三个方面:
首先,机器学习模型通常不希望数据的各个维度之间存在相关性。例如,假设我们正在训练一个线性回归模型,如果输入数据 \(x_1\) 和 \(x_2\) 高度相关,比如 \(x_1 = 3 \times x_2\),我们会发现模型中的系数 \(a\) 和 \(b\) 有很多可能的组合可以产生相同的预测效果。比如,\(a = 1\),\(b = 4\) 和 \(a = 0\),\(b = 7\) 会给出相同的结果。由于有无数种这样的参数组合,模型会变得不确定,失去优化方向。
通过主成分分析,数据中的相关性会被消除。以我们的例子为例,PCA 会将 \(x_1\) 和 \(x_2\) 中的相关性去除,最终保留一个维度(比如 \(x_1\)),而另一个维度(\(x_2\))则会变为 0,从而消除了多余的相关性,使得模型训练变得更加稳定和有效。
其次,通过将这些接近 0 的维度去掉,我们也可以降低数据的维度,因此降低模型的训练计算量,提高模型的训练效率。这种降维处理帮助去除了冗余的特征,使得模型更加简洁、快速,同时减少了过拟合的风险,提升了模型的准确性。
因此,PCA 既可以提高模型的训练效率,又可以提高它的准确性,是一种非常有效的数据预处理方法,广泛应用于机器学习中。希望大家能够充分理解并应用这一技术。
最后,利用 PCA 可以进行表征学习。通过对高维数据(例如单词的共现矩阵)进行降维,PCA 能够将原本维度非常高的数据转换为更简洁的表征。这样,数据的核心信息得以保留,而冗余和噪声被去除,从而方便后续的分析和模型训练。
举个例子,在自然语言处理(NLP)中,单词的共现矩阵通常是一个高维的稀疏矩阵,表示不同单词之间的共现关系。通过对这个矩阵应用PCA,我们可以得到一个低维的、更加紧凑的表示,这种表示能够有效捕捉到单词之间的语义关系,而不需要处理过于复杂和高维的原始数据。下面画出了一些国家及其首都的单词经过 PCA 降维后的二维向量的位置。
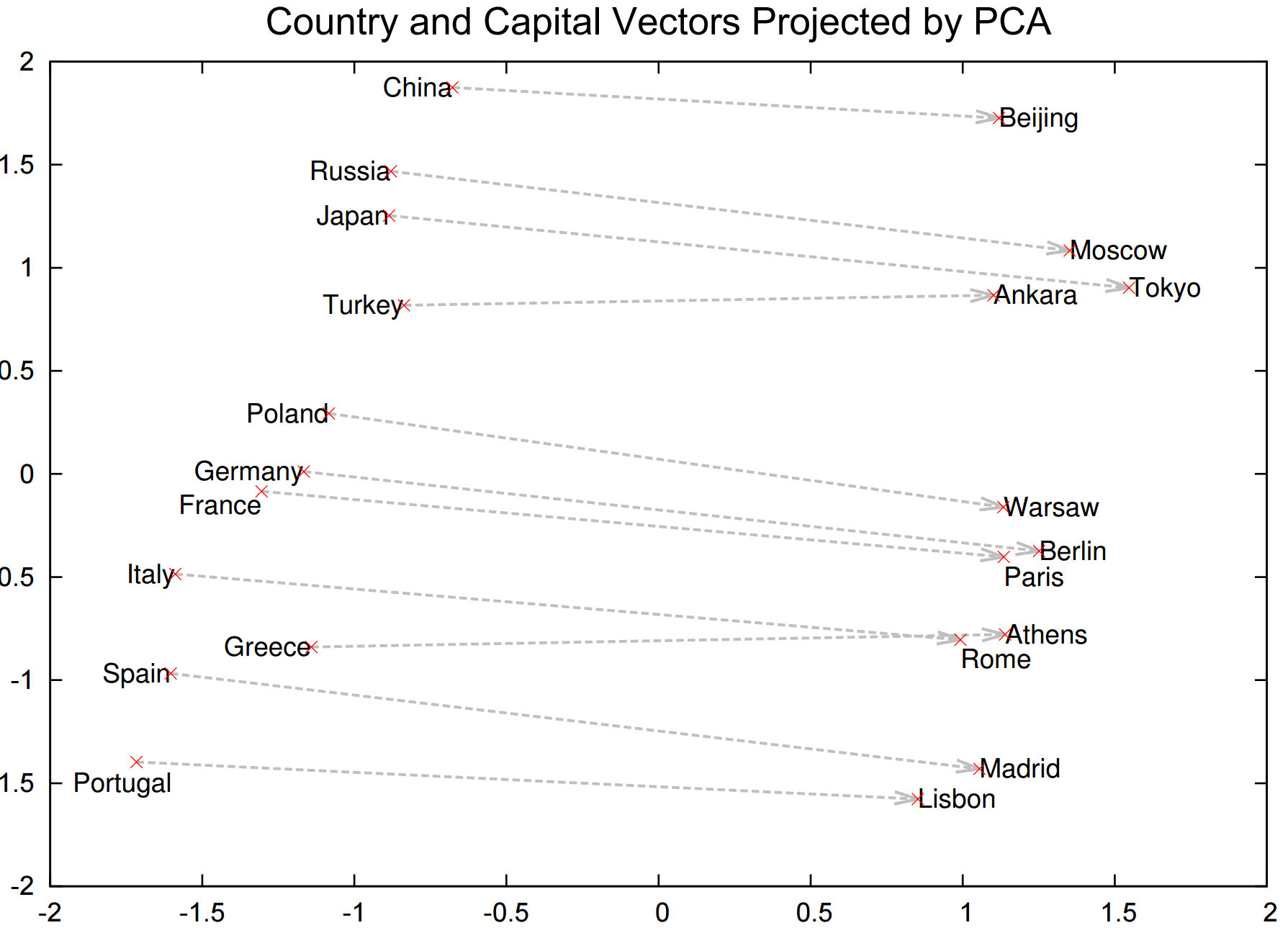
如上图所示,通过 PCA 降维后,这些单词的位置体现了它们的语义信息,比如,左边都是国家,右边都是首都;而且,从一个国家到其对应的首都的向量是差不多的。这就为后续的自然语言理解提供了很好的基础。
因此,PCA 降维不仅提升了计算效率,还能够提高模型的性能,尤其在大规模数据集上非常有用。因此,PCA 不仅是数据预处理的工具,还是表征学习中不可或缺的一部分。
半监督学习:结合有标签和无标签数据
最后,我们来看半监督学习。在实际应用中,打标数据往往是有限的,且打标工作费时费力。而与此同时,我们又有大量没有标签的数据。这时,半监督学习就能发挥作用。
半监督学习的核心思想是,首先从大量无标签数据中挑选出一部分进行打标,然后利用这些打标数据和未打标数据的内在规律,充分挖掘和利用标签数据的价值。通过这种方式,半监督学习能够在标签数据稀缺的情况下,利用无标签数据来提高模型的性能。下图画出了一个示例。
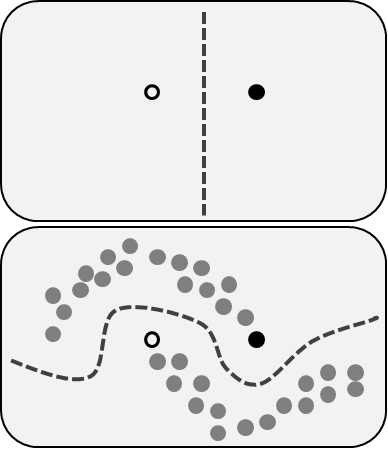
如上图中下面的子图所示,我们的数据有着很特别的规律:它可以被分为两个部分。在这两个部分的内部,数据之间互相靠得很近,连绵不绝;而两个部分之间,有着一条鸿沟。因此,我们只需要像上图中上面的子图所示的那样,选择两个数据进行打标,就可以学出来所有数据的类别。这就结合了少量打标,又充分地利用了所有数据。这就是半监督学习。
简而言之,半监督学习通过结合少量打标数据和大量无标签数据,不仅减轻了打标的负担,还能显著提升模型的准确性和泛化能力,是一种非常有效的学习方法。
增强学习:通过回报学习
最后,我们来看增强学习。增强学习是一种基于“回报”的学习方法。回报其实就是奖励,它帮助学习主体通过反馈不断改进自己的行为。就像我们训练小狗一样,当小狗做对了某个动作,我们给它奖励;如果做错了,就给它批评。通过这种方式,小狗逐渐学会了正确的行为。
在人工智能的训练中,增强学习的原理是类似的。例如,训练一个机器人或无人驾驶汽车时,它们的目标是最大化回报。假设一辆无人驾驶的汽车撞上了隔离栏,我们就会给它一个负回报(比如扣分);如果它避免了碰撞,就给它一个正回报(比如加分)。通过这种反馈机制,机器人或车辆会不断调整自己的行为,最终学会避免撞隔离栏。
增强学习模拟了人类和动物的学习过程,通过不断的试错和反馈,帮助智能体逐步提高性能。比如,AlphaGo 就是增强学习的一个典型应用。它通过与自己对弈(即两个机器人互相下棋),在数百万盘的对局中不断改进策略。当它在某盘棋中输了,它就会根据结果进行调整,逐渐提高自己的水平。正是通过这种自我对弈的方式,AlphaGo 才能战胜顶级围棋选手如柯洁。
增强学习不仅应用于围棋,还广泛应用于机器人、游戏、自动控制等领域。近年来,机器人技术发展迅速,但依然存在一些限制。例如,由于机器人的关节灵活性和物理限制,它们目前仍然难以完成一些非常精细和灵活的任务。
多臂老虎机
多臂老虎机(Multi-Arm Bandit)问题是一种特殊的增强学习算法,适用于需要在多个选择中作出决策的场景。假设你走进一个游戏厅,面对一排老虎机,你需要选择哪个机器来玩。这个问题的核心是如何在有限的资源(比如手中的币)下,找到赢率最高的机器,从而获得最大的回报。
多臂老虎机问题可以分为两部分策略:
- “利用”:选择已经知道赢率最高的老虎机,最大化已知的回报。
- “探索”:尝试那些还没有充分探索过的老虎机,可能会发现更高的赢率。
关键在于如何平衡好“利用”和“探索”的关系。如果只顾着“利用”现有的知识,可能错失更高回报的机会;而如果过于“探索”,则可能浪费资源而没有发现最佳选择。因此,找到一个合适的平衡点是解决多臂老虎机问题的关键。
UCB(Upper Confidence Bound)算法是多臂老虎机问题中的经典算法之一。该算法的核心思想是比较不同老虎机赢率的置信区间上界。在每一轮选择时,UCB 算法会选择赢率上界最高的老虎机进行尝试,这个上界考虑了两部分因素:
- 平均赢率(均值):即老虎机的历史表现,代表了已知的回报情况。
- 探索空间(标准差):反映了该老虎机仍未完全探索的潜力,鼓励探索那些尚未充分试验过的机器。
由于 UCB 算法使用的是置信区间的上界,它自然地平衡了“利用”和“探索”。在初期,算法倾向于更多探索尚未了解的老虎机;随着时间的推移,它会更多地选择那些赢率较高的老虎机,直到找到最优的选择。
这种综合考虑了平均赢率和探索空间的策略,使得 UCB 算法在实践中能够取得非常好的性能,并且有效解决了多臂老虎机问题中的探索与利用的平衡。
增强学习 在多个领域中有广泛的应用,尤其是在机器人、游戏 和自动控制方面。以下是几个典型的应用例子:
-
游戏:OpenAI Dota 是一个著名的案例,展示了增强学习如何在复杂的多人竞技游戏中应用。OpenAI 的 Dota 2 AI 能够通过与人类玩家和其他 AI 进行对抗,不断改进自己的策略,最终达到接近甚至超越人类玩家的水平。该系统使用了深度强化学习算法,通过大量自我对弈来学习最佳策略。
-
学习行走:DeepMind Walk 是另一个著名的应用,展示了如何使用增强学习训练机器人进行行走。DeepMind 使用强化学习训练了一种机器人,使其能够通过不断的试错学习如何稳定地行走。这个过程需要通过反馈机制来调整机器人的行动策略,避免摔倒,并逐步提高其行走的效率和稳定性。
这些应用展示了增强学习在处理复杂决策问题时的强大能力,无论是面对实时战略游戏中的复杂决策,还是控制机器人进行物理运动,增强学习都能够通过不断的试错和回报反馈来优化智能体的行为。
挑战
增强学习在应用中也面临一些挑战,主要包括以下两种:
-
收益会有延时:在增强学习中,智能体的行为可能在短期内没有明显的反馈,甚至可能直到很长时间后(例如多个步骤或回合之后)才会获得最终的奖励。这种延时反馈使得智能体难以立即知道自己的行动是否有效,学习过程会变得更为复杂和缓慢。举个例子,在自动驾驶中,某些错误的行为可能直到几分钟后才会带来反馈(如撞到障碍物),而机器人需要从这些延迟的反馈中提取出有价值的信息。
-
收益反馈稀疏:在某些环境中,反馈非常稀疏,即智能体收到的反馈不足。例如,学生在学习过程中,可能只有在期末考试时才知道自己学习的成果,而在日常学习中没有即时的反馈。类似的,在一些应用场景中,智能体的行动可能只有在很长时间后才能获得一次奖励,导致智能体很难从中获得有效的学习指导。这种稀疏的奖励会增加学习的难度,使得智能体需要更长的时间来积累经验并找到最优策略。
这两种挑战使得增强学习的应用更加复杂,因为它需要智能体具备长时间的探索能力和更高效的反馈处理能力,以应对延时和稀疏的奖励。
小结:学习类型
机器学习有种学习类型:
-
有监督学习:已知正确答案(标签),通过已标注的数据进行训练,学习目标是根据输入数据预测或分类。
-
无监督学习:从纯数据中发现规律,没有已知标签,主要用于数据的聚类、降维或异常检测等任务。
-
半监督学习:利用大量没有打标的数据,结合少量已标注数据进行训练,适用于标签获取成本较高的场景。
-
增强学习:通过智能体与环境的互动进行学习,智能体根据奖励或惩罚调整行为策略。
这四种学习类型在应用中各具特色,根据不同的任务需求选择合适的学习方法,可以有效提升机器学习的效果。
| Index | Previous | Next |