人工智能的视觉模型
本节首先介绍人工智能的视觉模型的历史,然后介绍目标定位、检测、识别、分割、风格迁移等机器视觉算法和模型。
起源
计算机视觉领域的起步可以追溯到20世纪60年代。第一个计算机视觉项目是在麻省理工学院(MIT)进行的。这是在1966年的一个暑期项目中发起的,目的是研究如何让计算机“看见”和“理解”图像。尽管项目的目标在今天看来显得过于雄心勃勃,但它为计算机视觉领域奠定了基础。下图是当时的项目文档:

在这个项目中,研究者希望通过算法模拟人类视觉的基本功能,例如识别物体的形状和位置。他们尝试用计算机处理简单的二维图像,试图让机器理解基本的几何形状,如三角形、正方形和圆形。研究者通过设计简单的数学模型,让计算机能够分析这些几何形状的特征,并根据这些特征进行分类。
尽管由于技术限制,项目的实际成果有限,但它开辟了计算机视觉的研究方向,并揭示了让机器理解视觉信息的巨大挑战。正是在这些早期探索中,人们认识到图像处理和模式识别的复杂性。
数据集的出现与基准测试
2000年左右,计算机视觉领域进入了一个重要的阶段——研究人员开始构建和发布公开的数据集,以推动技术的进步。这些数据集被用作基准测试(Benchmarking)的基础,研究者们可以通过这些数据集评估算法的性能,并通过比赛促进技术创新。
其中,加州理工学院(Caltech)发布了早期的一些经典数据集,例如 Caltech101 和 Caltech256。这些数据集包含了不同类别的图像,例如飞机、人脸、动物、建筑物等,每个类别有几十到几百张图片。这些数据集的特点是内容相对简单,但足以帮助研究者开发算法并测试它们的分类能力。
这些数据集的意义在于,它们为研究者提供了一个统一的基准,大家可以在相同的条件下测试算法的性能。通过对比结果,不同的团队可以快速发现问题,优化模型,并推动视觉技术的发展。例如,加州理工数据集不仅用于物体分类,还用于研究特征提取和图像表示的方法。
此外,这一时期的其他著名数据集还包括:
- MNIST:手写数字识别数据集,由纽约大学的 Yann LeCun 等人提出,包含 0 到 9 的手写数字图像,是早期机器学习的经典测试平台。
- PASCAL VOC:目标检测数据集,包含多种场景中的目标物体,用于推动目标检测技术的研究。
这些数据集的推出,不仅为研究者提供了丰富的素材,还通过组织公开竞赛(如 ImageNet 挑战赛)激励了算法的不断改进。
2009年,斯坦福大学的李飞飞教授提出了一个具有里程碑意义的计算机视觉数据集——ImageNet。这个数据集推动计算机视觉从小规模实验迈向大规模图像理解,彻底改变了研究者对视觉模型训练和评估的方式。
ImageNet 数据集包含了超过 1400 万张高质量的图像,这些图像覆盖了 20000 类物体,从常见的动物(如狗、猫、鸟),到日常用品(如椅子、杯子、手机),几乎囊括了人类生活的方方面面。其中,每一类都包含数百张到数千张图片,涵盖不同的场景和视角。数据的标注是基于 WordNet 提供的语义分类结构,确保了类别定义的科学性和一致性。
ImageNet 还从中精选了一个子集,用于举办 ImageNet 挑战赛(ILSVRC)。这个子集包含约 1000 类物体,每类有 1000 张图片,是经典的分类任务标准之一。
该数据集的难度在于:
- 规模巨大:ImageNet 的图像数量远远超过此前的数据集,如 Caltech101 和 PASCAL VOC。这种规模要求研究者设计更强大的算法和硬件来处理庞大的数据量。
- 多样性强:数据集中的图像来源广泛,涵盖了各种角度、光线和背景。例如,同一种动物可能出现在森林、沙漠或室内场景中。
- 细粒度分类:ImageNet 的类别包含了很多相似的物体。例如,不同品种的狗可能被分为几十个类别。这对模型的细节识别能力提出了更高的要求。
- 高标注质量:ImageNet 的标注过程是由人类完成的,确保了每张图片都与正确的标签匹配。尽管如此,数据规模依然为机器模型的学习和泛化带来了巨大挑战。
ImageNet 的诞生不仅为研究者提供了规模空前的数据资源,还通过其举办的年度挑战赛(ILSVRC),激励了深度学习模型的发展。
下图是各个数据中图片的示例。

下图是 ImageNet 的数据示例。


如上图所示,ImageNet 的图像识别难度较难。2012 年,加拿大人工智能学者 Geoffrey Hinton 和他的两位博士生 Alex Krizhevsky 和 Ilya Sutskever 提出了AlexNet,这是第一个在大规模数据集 ImageNet 上取得显著成功的深度卷积神经网络(CNN)模型。它的表现震惊了全球,标志着深度学习在计算机视觉领域的崛起。
目标定位(Localization)
目标定位任务输入的图片中只有一个目标。该任务的目标是返回这个目标的边界框(Bounding Box)的四个坐标以及目标的类别。如下图所示,我们就是想获得图中小狗的边框。

目标定位模型的设计如下:
首先,为了获得 Box 的四个坐标,我们将其作为一个“回归”问题,即预测这四个坐标的值。即边界框(Box)回归。此时,边界框由目标的四个坐标(如 \([x_{\text{min}}, y_{\text{min}}, x_{\text{max}}, y_{\text{max}}]\))定义。我们将预测这些坐标的过程视为一个回归问题,通过深度学习模型直接回归得到这些数值。
其次,为了评估 Box 预测的准确性,我们常采样的评估方法是 IoU(Intersection over Union)。IoU 衡量预测的边界框与实际目标边界框的重叠程度,其公式为: \(\text{IoU} = \frac{\text{预测框与真实框的交集面积}}{\text{预测框与真实框的并集面积}}\)
IoU 越高,表示定位越准确。
最后,我们采用的损失函数是 Box 坐标的回归损失和目标类别的分类损失的加权和。其中,回归损失表示边界框坐标预测的误差,通常使用均方误差(MSE)。分类损失表示预测目标类别的误差,通常使用交叉熵损失(Cross-Entropy Loss)。总体损失是这两者的加权和: \(L = \text{MSE(Box)} + \text{CrossEntropy(Class)}\)
目标定位最经典的方法是 OverFeat 算法。OverFeat 大量地采用“滑动窗”技术。
它的算法包括三部分:
首先,做分类预训练:在不同的尺度和位置应用滑动窗,对输入图片进行目标类别分类。
其次,做边界框回归:用预训练获得的模型,提取特征,用不同尺度、位置的滑动窗,做目标位置的四个坐标的回归;
最后,综合各滑动窗的分类和回归结果,根据预测概率选择最优边界框,去除冗余的框(如使用非极大值抑制,NMS),获得对 Box 的最后预测。
在具体的实现上,我们利用 CNN 卷积操作快速地实现滑动窗操作。滑动窗技术传统上是逐块处理图片,但在深度学习中,滑动窗操作可以通过 CNN 的卷积操作快速完成,因为 CNN 的卷积核在图片上移动的过程,本质上就是一种高效的滑动窗操作。所以 OverFeat 的运行速度很快。
而最后的分类和回归,通过 1x1 卷积完成。
总之,OverFeat 充分利用 CNN 的并行计算能力,实现高效滑动窗,实现速度很快;同时,它结合了分类和回归,既可以预测目标类别,也可以精确定位目标位置。这些都是开创性的,为后续目标检测算法(如 YOLO、Faster R-CNN)奠定了重要基础。
目标检测(Object Detection)和识别
和目标定位不同,目标检测的输入图片中有很多目标。因此,模型需要从一张图片中检测出多个目标,输出每个目标的类别和边界框(Bounding Box)。这一任务比目标定位更复杂。
目标检测的性能评估指标是 MAP(Mean Average Precision),即:先计算每一类目标的AP(Average Precision),然后对所有目标类别的 AP 取平均值,得到整体性能的评估值。
目标检测最经典的算法有三个。我们下面分别介绍它们。
YOLO
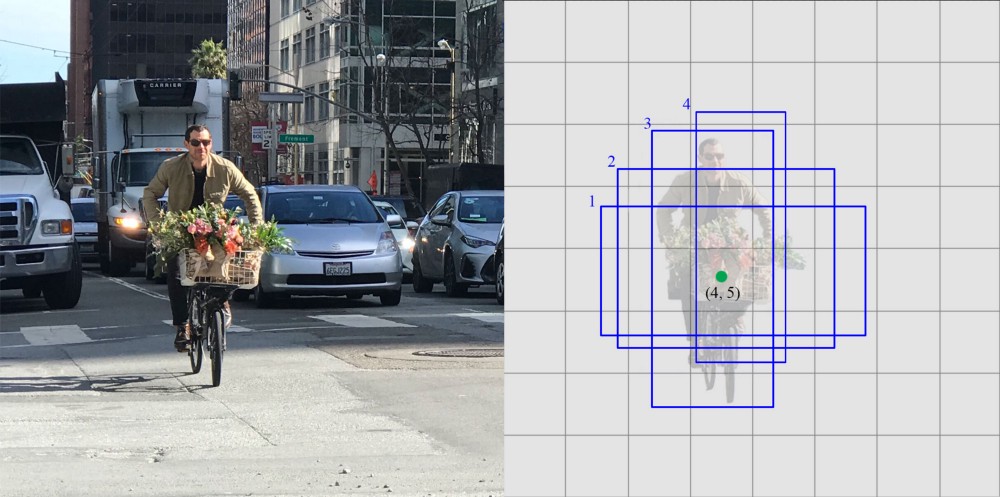
首先是 YOLO(You Only Look Once)。它把图片切成小块,每块做自己的目标定位,输出四个坐标、IoU、标签,然后再组合,得到目标的边界框坐标(Box)和类别。下图画出了它工作的示意图。
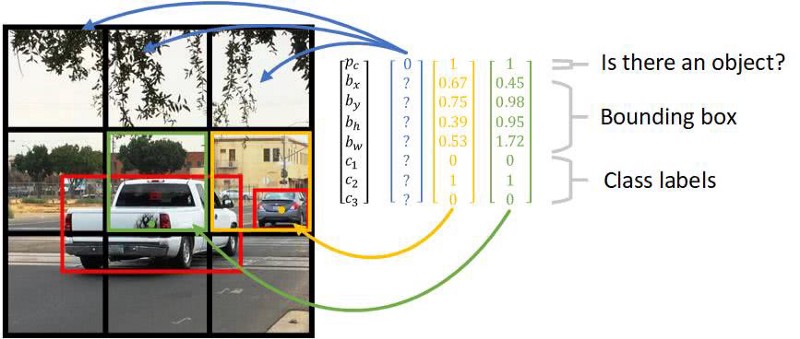
如上图所示,对图中的每一个小块(比如绿块、黄块),它都做自己的目标定位,识别目标是否出现,如果出现,还给出目标边框的左边和目标类别标签。
对每个小块进行了识别后,它再综合各个小块的识别结果和类别概率地图,然后进行合并,得到最终的识别结果。下图画出了这一过程。
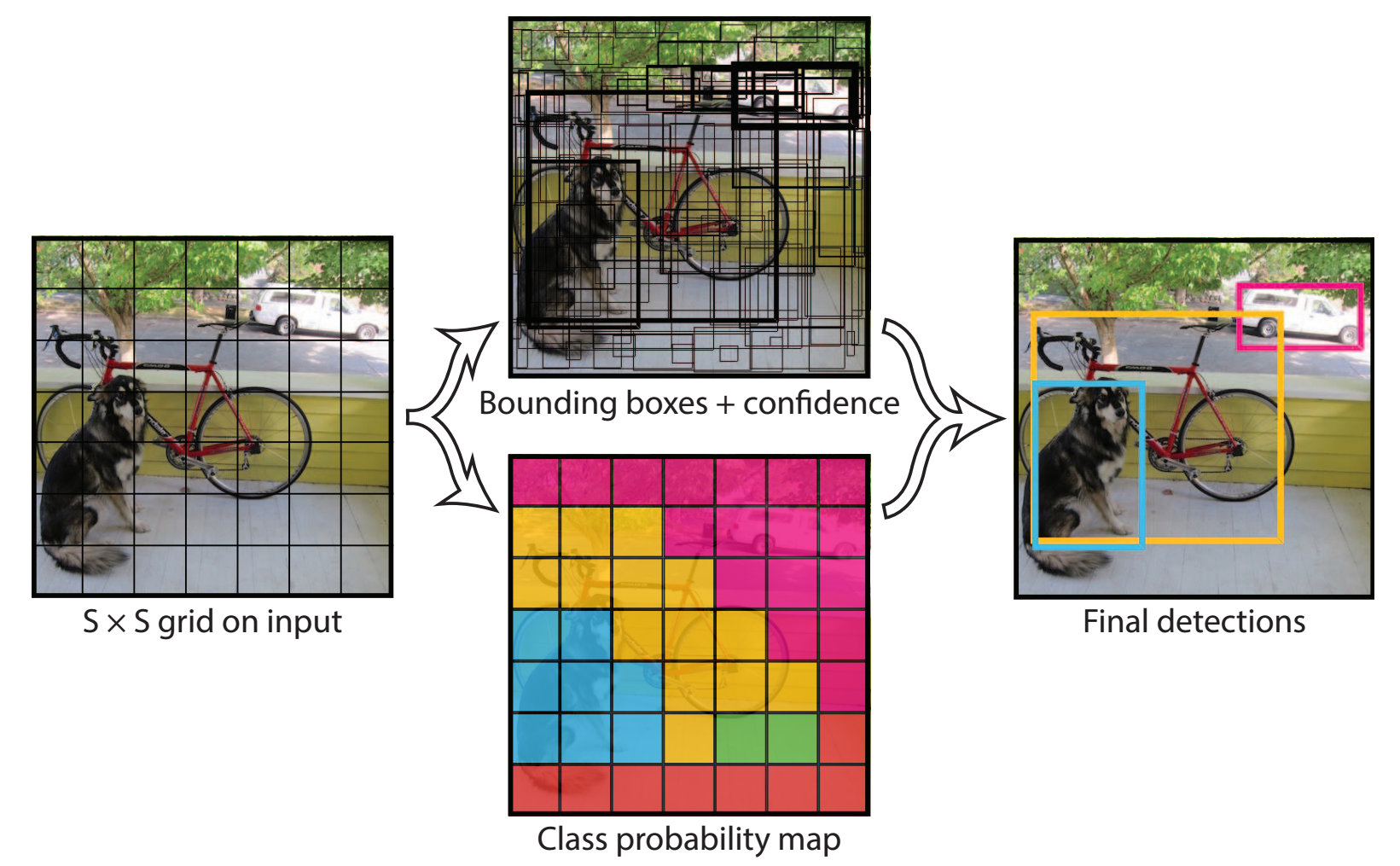
因此,YOLO 能够单阶段完成所有工作,不需要多步迭代,所以速度快,适合实时检测。
R-CNN
Fast RCNN 在图片上做滑动窗,抽取可能的区域,然后计算这些区域的 CNN 特征,并将提取的特征送入区域分类器和回归器,预测目标类别和边界框位置。下图画出了它的工作原理。
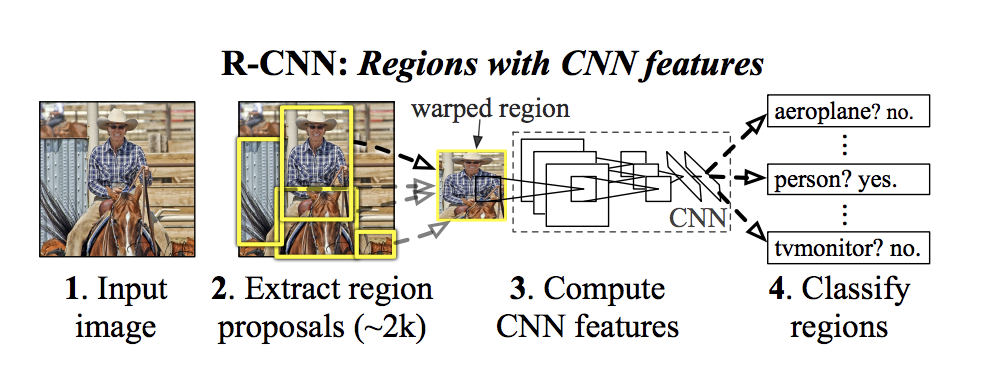
如上图所示,Fast R-CNN 首先通过特定方法(如 Selective Search),生成可能“感兴趣的区域”(Region of Interest:ROI),大约 2 千个。然后在这些区域上运行 CNN 进行特征提取,并将提取的特征送入分类器和回归器,预测目标类别和边界框位置。因此,相较于传统滑动窗方法,该方法大幅减少了计算量。
此外,Fast R-CNN 在不同的 ROI 之间共享卷积特征,进一步提升了效率。下面是该方法的原理图。
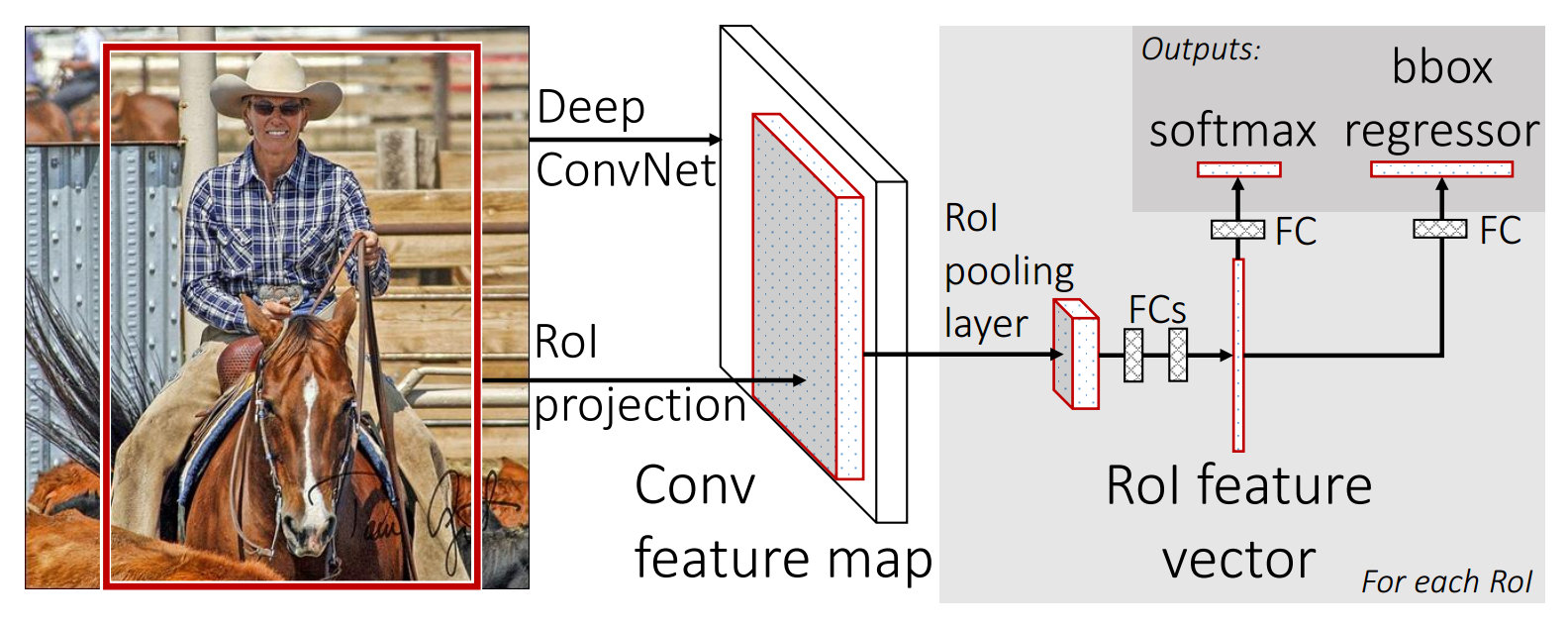
然后,Faster R-CNN 不固定地估计 2 千个区域了,因为这些区域还是太多。相反,它基于 CNN 的输出,预测“感兴趣的区域”,以获得更准的“建议区域”。因此,它新加了一个 Region Proposal Network 来预测 Region,替代了 Fast R-CNN 中的手工生成步骤(如 Selective Search)。然后在这些建议区域上运行分类器和回归器,预测目标类别和边界框。下面是该模型的工作原理图。
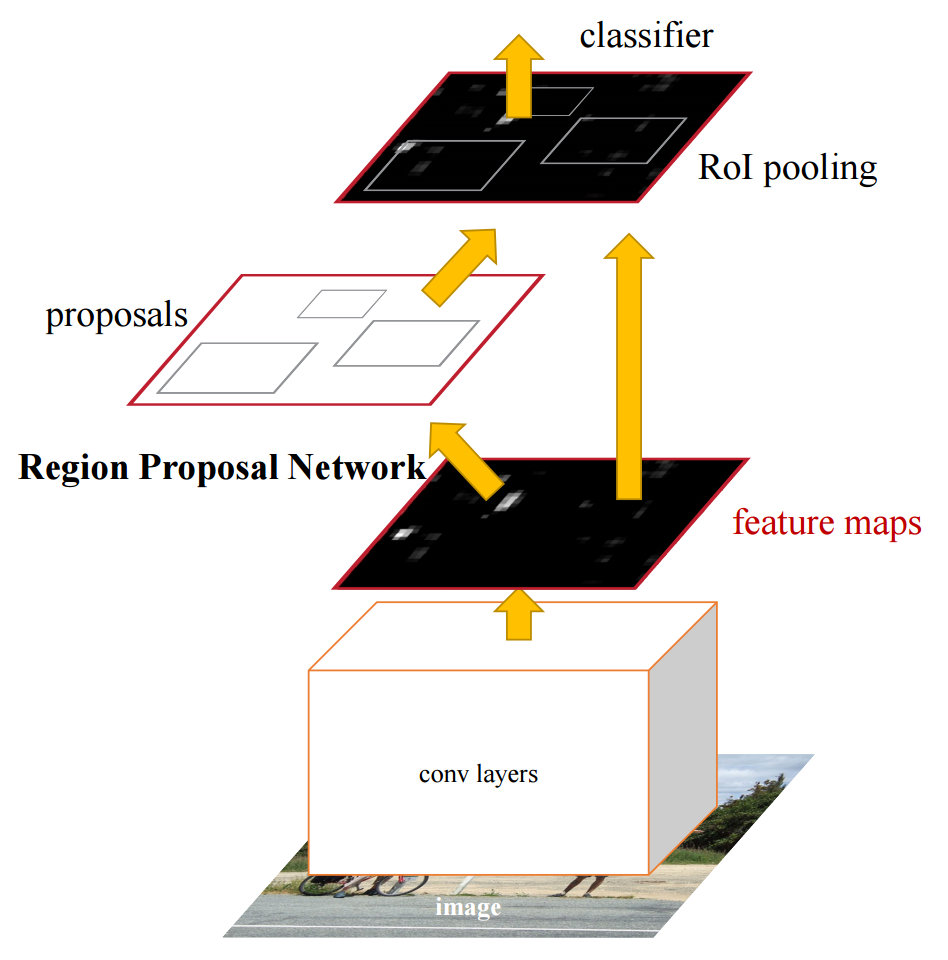
因此,Faster R-CNN 的 Loss 函数中包括四部分:1)边界框的回归误差(回归 Loss)。2)边界框类别的分类误差(分类 Loss)。3)RPN 中建议区域的回归误差和分类误差。
总之,Faster R-CNN 通过自动化生成建议区域,提高了模型的效率和精度。其精度优于 Fast R-CNN,计算量更小。
SSD
最后是 SSD(Single Shot Detection),它直接分类位置和 Box 的形状。像它的名字(Single Shot)所说的那样,它是一种单阶段目标检测方法,直接预测目标的类别和边界框位置,无需单独生成建议区域。这一方法和 YOLO 类似。
具体来说,SSD 在多尺度特征图上运行 CNN,检测不同大小的目标,同时输出边界框和目标类别的预测。这样做的优点是:它比 YOLO 更快,同时保持较高的精度,在小目标和大目标的检测上表现优异。下图是它的工作示意图。
总体上来说,各种目标检测算法在效率和精度上各有侧重:YOLO 注重速度,适合实时应用。Fast R-CNN 和 Faster R-CNN 注重精度,适合更复杂的场景。SSD 则是速度与精度的折中方案,成为目标检测的重要基准。这些算法为深度视觉模型的广泛应用(如自动驾驶、安防监控等)奠定了坚实基础。
语义分割(Semantic Segmentation)
语义分割是将图像中的每个像素分类,并根据每个像素所属的类别,将整个图像按对象的语义进行分割。例如,在一张包含狗、猫、背景的图片中,语义分割将把所有的狗像素标记为“狗”,所有的猫像素标记为“猫”,而背景则被标记为“背景”。下图画出了一个语义分割的结果。

如上图所示,语义分割把小狗从背景中分割出来了。
语义分割与实例分割(Instance Segmentation)是不同的任务。语义分割将同一类别的多个实例合并在一起,比如,所有“狗”的像素会被标记为同一类,而不区分这些“狗”之间的不同。而实例分割更加细致:它不仅识别出每个对象的类别,还区分同一类中的不同实例。例如,对于图片中的多只“牛”,实例分割不仅识别出哪些像素是“牛”,还能够区分每一只牛的边界,并单独标记每只牛。下面是实例分割的示例:

如上图所示,相同语义的多个对象(比如“人“),会被实例分割分为不同的实例。
语义分割的挑战是如何准确地对每个像素进行分类,尤其是在物体边缘或者相似物体之间有重叠的情况下。
语义分割常采用两种模型:FCN 和 U-Net。我们下面分别介绍它们。
FCN(全卷积网络)
FCN(全卷积网络)采用瓶颈结构,包括下采样(Downsampling)和上采样(Upsampling)操作。
它首先对图片做 Downsampling,把图片转变为很多“低清晰度”卷积层。每个卷积层就是一个 Channel。然后,将这些 Channel 合在一起,进行 Upsampling。这样就可以合并图片各个部分的上下文信息,聚合具有相同语义的图片相邻像素,获得图像语义的轮廓。这非常有意思。
它首先对输入图像进行下采样,将图像的分辨率降低,生成多个“低清晰度”的卷积层。每个卷积层就成为一个“通道”(Channel)。这些通道包含不同分辨率的图像高层特征,可以帮助网络理解不同尺度的图像上下文信息。
它然后对这些低分辨率的特征图进行上采样,恢复图像的空间分辨率。这样就可以从图像的不同尺度邻居位置提取上下文信息,聚合具有相同语义的邻近像素,生成图像的语义轮廓。
在上采样过程中,FCN 常用两种方法:
第一种方法是转置卷积(Transpose Convolution):通过逆卷积操作来增加图像的分辨率。例如,先对输入图像进行零填充(Padding),再进行卷积操作,得到更高分辨率的输出。具体的转置卷积操作是将卷积核做转置,生成更大的特征图。下面是一个例子:
输入矩阵:\(X = \begin{bmatrix} 0 & 1 \\ 2 & 3 \end{bmatrix}\)
卷积核:\(K = \begin{bmatrix} 0 & 1 \\ 2 & 3 \end{bmatrix}\)
为了执行转置卷积,我们首先将输入矩阵填充为零,变成如下 4×4 矩阵:
\[X_{pad} = \begin{bmatrix} 0 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 \\ 0 & 2 & 3 & 0 \\ 0 & 0 & 0 & 0 \end{bmatrix}\]转置卷积的核心步骤是对卷积核矩阵进行转置:
\[K^T = \begin{bmatrix} 3 & 2 \\ 1 & 0 \end{bmatrix}\]然后,将 \(K^T\) 与 \(X_{pad}\) 进行标准卷积运算,最终得到输出矩阵 \(Y\):
\[Y = \begin{bmatrix} 0 & 0 & 1 \\ 0 & 4 & 6 \\ 4 & 12 & 9 \end{bmatrix}\]上面的示意图展示了转置卷积(Transpose Convolution)的过程:为了将输入2x2的矩阵变成3x3的矩阵,首先对其进行Padding,得到4x4矩阵,再通过转置卷积得到最终的3x3矩阵。这种技术在图像分辨率增强(例如超分辨率重建)或语义分割任务中非常常见。
第二种方法是 Un-pooling:Un-pooling 的操作基于最大池化(Max Pooling),它会记录下池化时选择的最大值的位置,然后在上采样过程中恢复这些位置的值,以保持空间结构。下图画出了 Un-pooling 的基本原理。

U-Net
U-Net 是一种在医学图像分割中非常常见的网络结构,特别适合进行高精度的语义分割任务。下图画出了 U-Net 的网络结构。
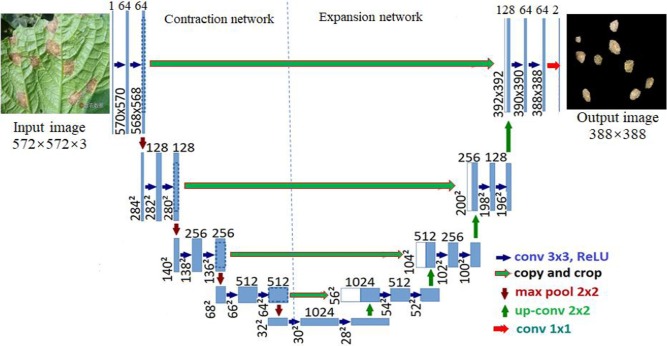
如上图所示,与 FCN 相比,U-Net具有以下独特的特点:
-
跳跃连接(Skip Connections):U-Net 的一个显著特点是它在下采样(Downsampling)和上采样(Upsampling)之间引入了大量的跳跃连接。这些跳跃连接将下采样阶段的特征图直接传递给对应的上采样阶段,确保网络在恢复空间分辨率时能够保留更多的低级特征。这种结构帮助 U-Net 提高了分割精度,尤其在图像的边缘部分。
-
Up-Convolution:与 FCN 不同,U-Net 的上采样操作不只是简单的转置卷积,而是通过可学习的Up-Convolution(上卷积)来生成更高分辨率的图像。Up-Convolution 的卷积核参数是可训练的,使得模型在进行分割任务时具有更强的灵活性和精确度。
小结
FCN 的关键优势是通过卷积操作直接处理图像的每个像素,避免了全连接层的使用,适合大规模图像处理。U-Net 则通过跳跃连接和可学习的 Up-Convolution,更好地保留了低级特征,特别适合需要精确边缘分割的任务,比如医学图像分割。这两种模型都在语义分割领域取得了显著成功。
目标检测和识别的挑战
目标检测和识别在实际中面临着许多挑战:
- 遮蔽:目标可能被其他物体部分或完全遮挡。例如,在街道场景中,一辆汽车可能被树枝或行人遮住,仅能看到局部特征。这种情况下,模型很难判断目标的完整形态并正确分类。
- 干扰与相似性:自然环境中的许多物体外观相似,容易导致模型混淆。例如:一只毛发蓬松的狗,其外形和拖把极为相似,可能被误认为是拖把。而蓝莓蛋糕的形状和色彩,与某些动物(如特定品种的小狗)有高度相似性,也容易被误判。这些“迷惑性”干扰对模型的泛化能力提出了较高要求。
- 噪声与恶劣环境:噪声和环境因素会对图像质量造成影响,例如雾霾、雨雪等天气条件会模糊图像细节,导致目标特征难以提取。光照不均或过暗的环境会导致目标的颜色和形状信息丢失。
- 多样性与复杂性:现实中的目标千差万别,变化多样。同一种目标可能以不同的角度、大小、姿态、背景出现,增加了模型识别的难度。复杂场景中的多目标交叠,以及背景中存在类似物体,也会让模型误判。
下图展示了一些示例图片,从中可以看出上述各种困难

尤其是下面的这种情况,很难把拖把和狗区分开来。

而下面这种情况,则很难把蛋糕和狗区分开来。

下图显示了云雾遮挡的情况

面对这些问题,目前常用的方案如下:
- 提升模型鲁棒性:通过使用更深的网络结构(如 ResNet、Transformer)和更优的训练方法,使模型能够应对遮蔽和干扰。
- 数据增强:在训练时加入噪声、旋转、翻转等数据增强手段,提升模型的泛化能力。
- 大规模数据集与预训练模型:如 ImageNet、COCO 等数据集,帮助模型在复杂场景中更好地提取特征。
- 融合多模态信息:将视觉与其他模态(如雷达、声学)结合,提供多维度的信息输入,增强目标检测效果。
风格迁移
风格迁移是一种有趣的深度视觉算法应用,允许我们将一张图片转换成类似某种艺术家的画风,例如将一张图片转变为梵高的风格。下图画出了一些示例。

风格迁移模型的基本思想是固定 CNN 的模型参数,通过调整输入图像(即 \(x\)),使得我们设定的损失函数最小化。具体而言,风格迁移的过程可以分为三个步骤:
-
图像编码:首先,使用 CNN 对原始图像 \(p\) 进行编码。以 VGG-19 网络为例,我们提取该图像在网络的前几层和中间层的激活值(特征图),得到 \(C(p)\),它代表了图像 \(p\) 的内容特征。
-
风格编码:接着,使用相同的 CNN 对风格图像 \(a\) 进行编码。我们同样提取该风格图像在前几层和中间层的激活值,并计算它们的 Gram 矩阵 \(S(a)\)。Gram 矩阵是一种协方差函数,用于度量不同特征之间的相关性。它反映了图像的风格特征。
-
图像合成:最后,我们通过优化方法调整输入图像 \(x\),使其在内容和风格上都符合我们的要求。具体来说,优化目标是使合成图像 \(x\) 的内容特征 \(C(x)\) 与原图像 \(p\) 的内容特征 \(C(p)\) 相同,同时风格特征 \(S(x)\) 与风格图像 \(a\) 的风格特征 \(S(a)\) 相同。通过这种方式,合成图像 \(x\) 就是融合了风格图像 \(a\) 风格的原图像 \(p\) 的变换结果。
这过程非常有意思,因为它能够让机器自动地将图像的风格转换为其他风格,同时保留原图像的内容。
存在的问题
当前的人工智能视觉模型在实际应用中仍面临一些问题,这些问题也越来越受到人们的重视。这些问题不仅关乎技术的改进,更涉及伦理和法律层面的深远影响。如何在未来平衡技术发展与社会责任,是一个值得深入思考的话题。
首先是准确率问题,模型在某些复杂场景下的表现仍不够理想,比如处理遮挡、低光照或多目标情况下可能会出现错误。一个典型的例子是 2018 年 7 月,美国公民自由联盟(ACLU)对亚马逊的人脸识别系统进行了测试。实验中,该系统将 535 名美国国会议员的面部照片,与 25,000 张公开的警方嫌疑犯照片进行比对,结果竟然有 28 名无辜的国会议员被错误识别为嫌疑犯。这相当于所有国会议员的错误率为 5.2%。更令人担忧的是,对于非白人国会议员,这一错误率高达 39%。
另一个广为人知的案例是特斯拉自动驾驶系统的一次致命事故。在这一事故中,一辆特斯拉汽车启动了自动驾驶模式。当时,前方有一辆白色货车试图左转穿过车道,如下图所示。

根据设计,特斯拉的自动驾驶系统应该识别出前方的货车并采取刹车措施。然而,由于系统未能成功识别出白色货车,因为与蓝天背景形成的对比度过低,这一关键场景被忽略了。最终,车辆没有刹车,直接撞上货车,导致驾驶员不幸身亡。车祸后的现场如下图所示。

这一案例引发了人们对自动驾驶技术安全性和可靠性的广泛讨论。尤其是图像识别算法在特定场景(如光照条件、颜色对比不足等)中的局限性,凸显了改进深度学习模型和提升技术可靠性的必要性。这不仅是技术问题,更关乎生命与伦理,是人工智能领域亟待解决的重要挑战之一。
识别错误在实际应用中也很容易引发公众的强烈不满。一个著名的例子是谷歌的图像识别系统曾将一张非洲裔用户的照片误识别为“大猩猩”,引发了巨大的争议。这一错误暴露出算法的训练数据可能存在不平衡的情况,导致它在处理不同肤色或特定人群的图像时表现不佳。面对公众的愤怒,谷歌迅速道歉,并采取措施改进其算法。然而,这一事件凸显了人工智能系统开发过程中需要更多关注数据多样性和偏见消除。人工智能的广泛应用必须以充分的测试和伦理审查为基础,避免类似错误伤害公众信任。
其次是隐私保护问题,在大规模数据采集和使用的背景下,如何保护个人隐私成为了一个重要挑战。例如,杭州一位市民曾拒绝在公园入口处进行人脸识别,并以此为由提起诉讼,呼吁对隐私权的保护。这一事件引发了社会关于人脸识别技术滥用的讨论。不仅仅是在国内,国际上对于隐私保护的呼声也在不断加强。2019 年 5 月 14 日,旧金山城市监督委员会以 8 票对 1 票通过了一项法令,禁止城市工作人员购买和使用人脸识别技术。支持者认为:“人脸识别技术对公民权利和自由的危害远远超过其声称的好处。这项技术将加剧种族不平等,并威胁到我们享有不受政府长期监控的权利。”这些案例表明,隐私保护在技术应用中的重要性正日益凸显。如何在技术发展和个人权利之间找到平衡,成为了一个亟待解决的问题。完善隐私保护法规,加强技术伦理审查,或许是未来发展的方向。
最后是公平性问题,模型可能会因为训练数据的偏差而在决策中表现出不公,这对不同群体可能带来负面影响。比如某些人脸识别系统可能对不同性别或种族的识别准确率存在显著差异,导致某些群体在生活中受到不公正的对待,例如被识别为危险人物。另一个例子是信用评分系统。一些金融机构的信用评分模型可能因为数据中的历史偏见,给经济欠发达地区的人群低分。这可能加剧社会不平等,阻碍这些群体的发展机会。
为了最大限度地确保公平,我们可以在模型训练时,确保数据覆盖不同的群体,避免单一或偏向的数据来源;引入公平性检测机制,定期对模型的输出进行审查,发现潜在的偏差问题;立法机构也可以制定相关政策法规,要求人工智能系统在关键领域中必须符合公平性标准。只有解决了这些问题,人工智能技术才能更广泛地服务于所有人,真正体现其社会价值。
课本
- Dive in Deep Learning,14. Computer Vision
课程材料
- 伯克利大学,计算机视觉 PPT,图像风格转换 Note
练习
- CNN 图片分类练习: 多伦多大学 Pascal Poupart 老师 CS480 深度学习课程的练习3。内容为 CNN 图片分类。代码已可以跑通。需要对代码进行如下修改:模型结构、激活函数、Dropout、优化器、CNN filter
- 简明人脸识别练习: 深度学习人脸识别开源库:号称世界上最简单的人脸识别库,三句代码就搞定。代码,中文简介,
- TorchXRayVision: A library of chest X-ray datasets and models. Classifiers, segmentation, and autoencoders. Github
- CheXpert competition models – attention augmented convolutions on DenseNet, ResNet; EfficientNet, Github
体验
- Gifsplanation - Explaining neural networks with gifs! Website
工具
- segmentation_models, PyTorch Github, 8.4k stars, Tensorflow/Keras Github, 4.5k stars
- Image Test Time Augmentation with PyTorch! Github
| Index | Previous | Next |